Enough with the introductions, for the rest of this post we will look at the best practices and recommendations. Applying these to your Process Builder processes ensures they will be readable and easily maintainable. The declarative nature of Salesforce lends itself to fast and agile development. Especially when we are modelling business processes that often require changing we need our processes to be logically organised, simple to read and understand, and easy to track and improve.
The goal is to make them simple to change and maintain without limiting our automation capabilities. For example, if we try to model every action into one big process it becomes hard to manage and restricts some of our capability. Alternatively if we model every tiny action as a separate process it becomes very hard to track what should be happening and we probably end up repeating work in many processes.
After building enough of these you start to notice a pattern, so you should think about four key types of processes and every process you build should fit into one of these categories.
- Initiators — These are processes that execute when a new record of a specific object are initiated. Use the naming convention *object_initiator when naming these processes
- Processors — These are processes that manage the primary lifecycle of an object. For example it would automate the actions for each sales stage in an Opportunity, or each status change of a Case. Use the naming convention #object_process.
- Actions — These processes execute the ad-hoc or random actions that may be required for an object. These actions don’t fit or relate to the overall lifecycle or progress of an object but may be grouped together logically. Use the naming convention !object_actions.
- Subprocesses — These are headless processes that are not executed via a state change but explicitly called from another process. We usually use these to easily reuse functionality in multiple places. Use the naming convention &object_subproc_xxx, where xxx describes the subprocess actions.
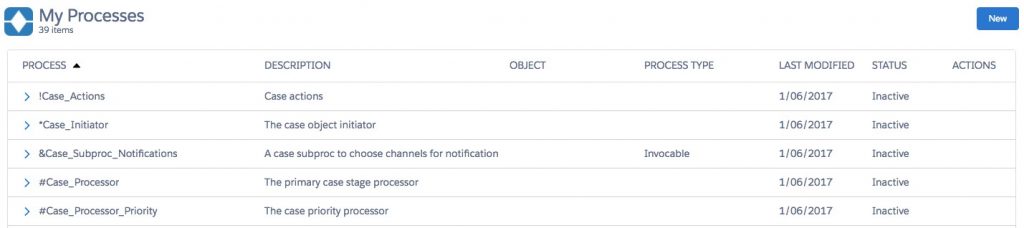
Defining these 4 types of processes gives us a framework for classification and a model for maintainability. For each object in Salesforce you will now have only these 4 types of processes in Process Builder. So in future, if the business asks for some change or action to occur when a new Contact record is created, I immediately know I can find the *contact_initiator process and make my changes there.
Lets look closer at how these four process types can be used.
Initiators — How to guarantee a consistent foundation
These are the most straight forward of the four process types because the state in which they execute is always when a new record is created.
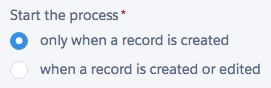
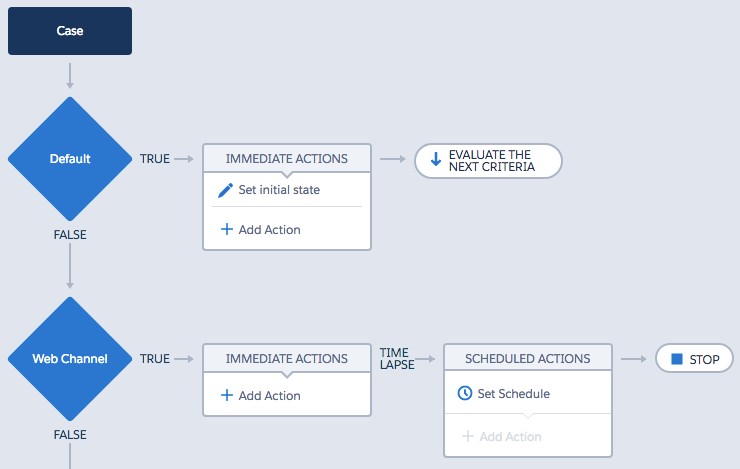
To ensure this is the case when creating an initiator process check the “only when a record is created” option on the initial process event. Strict adherence to this principle would mean you only have a single initiator process per object in your Salesforce Org.
Within your initiator process your primary IF statements (criteria nodes) should identify major differences in the object’s type. It may delineate between the object’s record types, or between some primary categorisation of the object. For example, it might be important to your business to differentiate between the channels a Case is created through. In which case your criteria nodes for a *case_initiator process may be each Case Channel e.g. Phone, Web, Email, Social, Chat (See Figure 6).
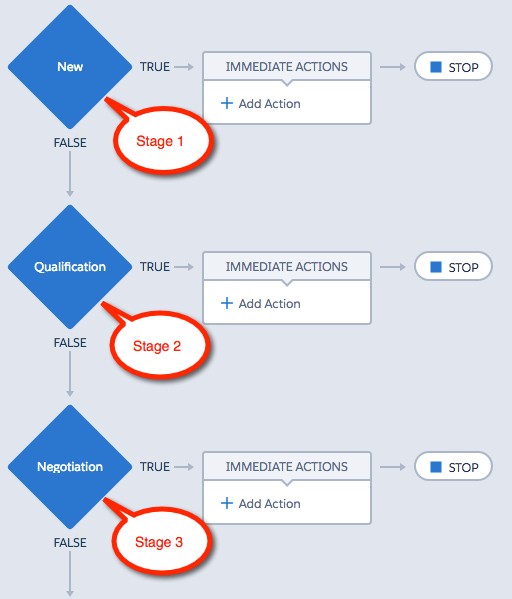
You may design your primary IF statements to be more complex by using two or more fields, for example ‘IF Channel = Email AND RecordType = Technical Complaint’. Be sure not to over complicate the criteria node statements, your process should be easily readable and match how the business organises the object.
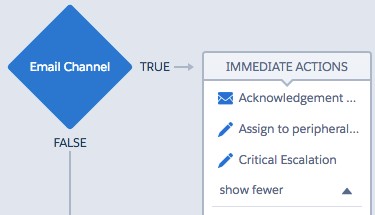
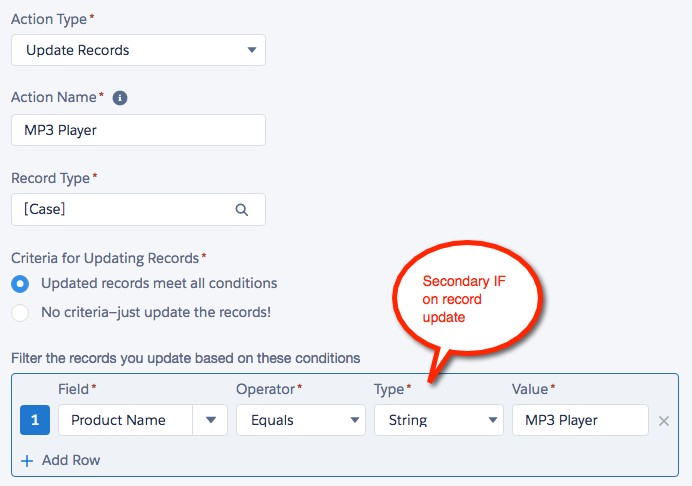
For further specification of record updates, secondary IF statements can be used. Each update can then optionally execute if it meets certain criteria. For example once you know the Case has a channel of Email, you could design a process to take three further actions (one always executes and two are conditional):
- Send an acknowledgement Email to the associated contact confirming receipt of the new Case.
- IF Product = Headphones THEN reassign Case to peripherals queue/team.
- IF Product = MP3 Player THEN escalate Case to ‘Critical’ (See Figure 8).
In this example step 3 only executes if the Case Channel is ‘Email’ and the Case Product is ‘MP3 Player’. Where you may have a number of actions that are not record updates, or occur in multiple action groups, you may want to design them as a subprocess and invoke them from each action group branch (more on these later).
Note that if you create scheduled actions you do not get the ‘Evaluate next criteria’ option. This makes your criteria filters mutually exclusive. Only one action group will execute for any new record. To avoid confusion you should ensure the criteria (primary IF) statements you define are always mutually exclusive regardless of if you use scheduled actions initially or not. This allows you to add scheduled actions in the future if necessary without major upheaval to your processes.
An exception to this rule is only viable in the first action groups as IF statements are executed in order. Sometimes it is necessary to take default initial actions for every new record created. So you may use the ‘Evaluate next criteria’ action group outcome within the first IF statement often coupled with the ‘No criteria — just execute the actions!’ condition.
In this way you can design your initiator process to segment the new records based on clear, primary filters (e.g. Channels and Record Types) so that your process is easily understood. Once segmented by the primary filters a process can conditionally automate different actions based on specific features of the newly created record.
Processors — how to engineer order amongst the chaos
Processors define the key stages of your business process. These should be the easiest to understand and possibly the most frequently used.
Processors should have one action group defined for each stage of your business process. Your criteria nodes statements should simply determine if the stage or status field is X and should use the advanced option to identify execution ‘only when the specified changes are made to the record’.
Simplistically this process says IF the stage has changed to X THEN do Y.
Often this process maps directly to a picklist field on an object. For example the Opportunity object often uses the Stage field to track the progress of an opportunity from initial qualification through to won or lost (See Figure 10). Often business rules are defined at each stage to validate if the opportunity is ready to progress and executives are possibly alerted if the opportunity changes stage and meets certain criteria (e.g. a big deal alert).
This pattern is very common in Salesforce applications. We see it in many use cases such as job candidates progressing through interview stages, events through planning stages, submissions through review stages, or projects through maturity stages.
Salesforce Path is often used in conjunction with a processor process. Path provides visual feedback and detail to a user viewing a record to see the current status of the record and the next steps required to progress the record to the next stage. When a user completes the required actions and updates the record status the processor process should fire.

Common actions that occur in the processor process are submitting the record for review, alerting relevant people, and updating associated records or fields.
Typically you only want any actions to occur once when the record enters the new stage, for this to occur you want to select the ‘execute the actions only when specified changes are made to the record!’ option in the criteria node.

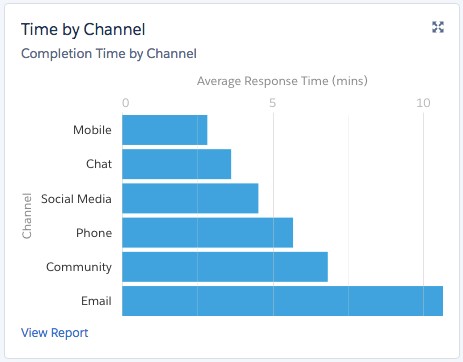
As processors map to key business processes, organisations are often interested in identifying opportunities for process improvement. As a result it is a good idea to plan for detailed reporting requirements on these processes. Organisations often want to report on:
- the average time spent in stage X
- the count of current records in stage X
- the overall process completion time
- all records that have been in stage X for longer than …
By reporting on this type of information organisations can identify bottlenecks and inefficiencies in their business processes, understand the behaviour of the system, or spot exceptions that need immediate attention. To enable this type of reporting we need to capture the history of transitions over time, not just the current state.
There are a couple of ways we can do this, the simplest is to add a timestamp field for each stage in the process, we can then update the timestamp when we complete that stage. This method has limitations if we allow the process to move forward and backward as the timestamps will be overridden and our reporting won’t match what actually occurred.
The best method is to enable Field History Tracking on the object, then select the field that is used to track the state of the process. Now modifying the state will add an entry to the History related list. All entries in the History related list will include the date, time, nature of the change, and who made the change. This allows for the level of reporting most organisations are looking for. Note the field history data is only retained for up to 18 months within Salesforce.

So what if an object needs more than one processor?
It is common for business requirements to necessitate multiple processors for an object. An example here might be Cases, we often see a processor to track the Cases current status #case_process_status and a processor to track the Cases current priority #case_process_priority. The execution of one may even indirectly invoke the other.
Another scenario is when an object has Record Types that dictate two different processes. Be more careful in this scenario, your goal should be to minimise the number of processors per object without losing readability. So, if there is a lot of overlap between the two processes (they have common states) then consider condensing the design into a single master processor, but if they are largely independent, then separate them.
We advocate the use of multiple processors per object where necessary, however a good architect should always be looking for ways to minimise their propagation.
Finally, like initiators, processors should be designed with mutually exclusive action groups. Avoid using the ‘Evaluate next criteria’ option wherever possible, as a record may only be in one state at any time it should not be relevant.
Actions — how to remove the risk of human error
Action processes are our catch all. All ad-hoc or independent automations should be modelled in the actions process.

Ideally we have one action process per object. Within the process each action group will be independent and here you should use the ‘Evaluate next criteria’ option as default. Think of the action process less like a process and more like a list of rules. We just bundle all the rules into a single ‘bucket’ we call the action process.
Generally the action process will execute tasks that occur once some manual action has occurred. Like when a record owner changes — alert the new owners manager and the old owner, or when one object is linked to another — update a counter on the parent, or if a value exceeds a limit — post a notification to chatter.
More advanced use cases can start using the confidence scores from Einstein to automate actions. Using Einstein in your processes makes your processes smart — meaning you are no longer hardcoding the rules into the process.

For example it’s possible to build a process that leverages Einstein Lead Scoring to route and prioritise your leads. Einstein Lead Scoring uses artificial intelligence to score your leads by how well they fit your company’s successful conversion patterns; so you don’t need to know which characteristics indicate a high priority lead, you don’t need to build a matching algorithm into your process, and you don’t need to modify the characteristics as they change — because Einstein will automatically and accurately do this for you based on the history of all previous leads!
This can all be achieved in a single action group within the object actions process.
Action processes become more complex when you add scheduled actions. To add scheduled actions you’ll need to have checked the ‘execute the actions only when specified changes are made to the record?’ option on the criteria node.
As action groups are assessed in order you can place all action groups that include scheduled actions at the bottom of the process. Note again that these are mutually exclusive, so ensure your criteria logic is sound.
Subprocesses — how to simplify the complexity
Subprocesses are simply processes that are invoked by other processes. When creating a new process choose ‘It’s invoked by another process’ from The process starts when drop down list.
There are many uses for subprocesses, they are far more than just a convenience. Typically employed for reusability, by bundling business logic into a subprocess, you can then call them anytime you need. This avoids rewriting the same logic in many places.
In her blog Jenwlee gives a nice overview of DRY (Don’t Repeat Yourself) principles using Process Builder subprocesses. The goal here is to increase maintainability and convenience by abstaining from duplicating logic actions in multiple action groups.
A common example is a subprocess that first checks a customers preferred contact method before sending notifications. This can then be executed from any object that has a relationship with Contacts. In this way the primary process decides when to notify the contact but outsources the logic of how to contact the customer (i.e. via email, sms, communities chatter message) to the subprocess.
Subprocesses also enable nested IF statements. So, a processor may invoke a subprocess when the state of an object changes, the subprocess can then further break down which actions to take. For instance we may only notify a manager if we are in state X and the value is above Y. Using subprocesses in this instance allows us to keep the criteria in our processor pure by maintaining its granularity at the ‘check for current state’ level, and then provide finer granularity logic (value is above Y) in the subprocess.
Note you can’t call scheduled actions in a subprocess so it cannot be used as a workaround to make action groups with scheduled actions compatible (non mutually exclusive).
Finally it is worth highlighting that you can call the same subprocess multiple times within the same action group. This feature can be very handy when you need to execute repetitive actions with slight changes. Think sending notifications to multiple people or updating multiple related records. Because immediate actions are executed in order (top to bottom), you can prepare the data then call the subprocess repetitively.
A more productive way of doing this may be to call a Salesforce Flow subprocess, rather than a Process Builder subprocess. The final best practice for subprocesses would be to ensure you use the right tool for the job, so we encourage you to get an understanding of Flow too as it is way more efficient at achieving some tasks that seem clunky in Process Builder.
Summary — go forth and automate
Salesforce Process Builder is a very powerful tool for automating business actions. Thinking of Process Builder as a state machine execution engine is a more accurate way of understanding how it models business processes, despite it’s name (a common problem for ‘Salesforce’).
Following the simple patterns outlined by the four process models above will ensure you are on the right path to developing maintainable and therefore more agile processes. As with any framework there may be situational exceptions that arise, but an understanding of these practical concepts will aid your thinking and solution design.
Have fun process building!
This is an exert written by and published on MEDIUM
